【秒杀】JWT-满足你水管服务器的状态信息携带方式
本文最后更新于:2025年10月8日 下午
引言
JWT,即为JSON Web Token,拆开来看,JSON是JavaScript的一种对象数据存储方式,Token则是令牌,组合在一起就是在Web应用上,使用令牌的JSON数据,乍一看还是有点抽象,
举个例子吧,你的产品需要一个卡密来激活,激活之后才可以请请求服务器,但是HTTP请求没办法告诉服务器我是谁,我曾经请求了没,所以每次请求都是全新的,服务器在回答之后相当于“失忆”了,我如何让服务器知道我是谁来确定用户?如果单纯使用前端安全性不高,比如用cookie告诉服务器我是Kevin,服务器觉得是就是,但是我可以改成自己是Elysia,服务器还真以为是Elysia,这样子玩显然行不通,因为用户可以随便更改cookie的信息。
因为篇幅限制,这里就不放太多的业务代码了,再然后提醒一下,本篇内容综合,需要先掌握系统的js知识才能继续往下看,包括不限于:SessionStorage,localstorage,cookie,crypto,JSON对象操作,nodejs
卡密激活场景
接下来就以网站最常见的一种卡密激活的请求的方式举例,某个服务器需要你激活,每次请求都需要携带这个卡密信息才能返回结果。
目前常用的几种方式是Session和JWT
Session
Session相当于一个缓存,当A用户请求服务器之后,服务器会暂时存储A的信息,并返回一个Session token,等到下次A携带这个Session token给服务器的时候,服务器就知道是A用户了,比如存储这个用户卡密到期日期,还有用户基本信息等等,这样服务器处理数据就依靠存储的信息。但是Session也有缺点,因为是存放在服务器端的,每次查找调用都会有点麻烦,而且在多服务器负载均衡的场景下,A用户请求A服务器没问题,但是B服务器有可能因为同步延迟没有同步A服务器的Session数据,导致B服务器不认识A用户了,这样一来服务器压力会变大;并且要实现多平台互通的时候,意味着Session也需要互通,这就需要不同服务器要同时使用一个数据库,加大了数据库的压力。
JWT-
JWT更为直接,把压力交给用户,直接把信息存在用户浏览器上,服务器只管解码,但是前面也提到了,直接存用户浏览器上非常不安全,很容易就篡改了,所以JWT在普通JSON数据的基础上,加入了Token这么一个玩意,保证了数据不被篡改。当用户确定开卡的时候,服务器签发一个JWT,上面标记了过期时间,用户ID和基本信息,当用户A请求的时候,就需要携带这个jwt请求服务器,服务器解码验证确定没问题,拿到基本信息处理就完毕,不再像Session那样还需要去找A用户那块Session存储,自然就方便快速很多。
JWT长什么样
数据结构
JWT,长这样
1 | |
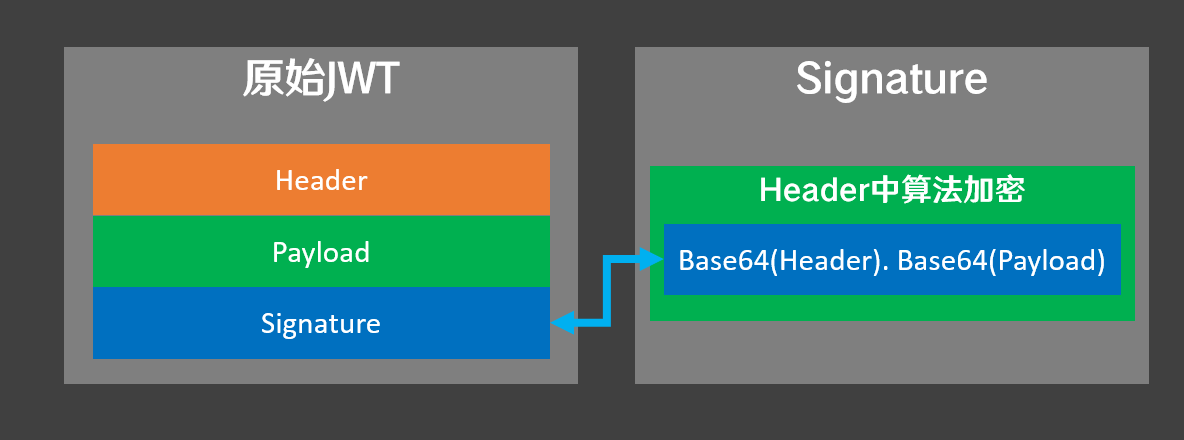
这一眼看上去乱七八糟的,不过,数据里面有两个点,数据的部分就是由.来分开的,分别叫做Header 头部,Payload 数据载荷,Signature 签名
上面这段数据的三部分如下:
1 | |
Header和Payload都是由原始数据Base64编码后得到的,但是由于Payload有可能出现base编码后的=符号,而为了兼容浏览器URL地址栏的位置防止被编码,可以描述为:=被省略、+替换成-,/替换成_,所以在编解码的时候需要用到Base64URL的算法。
把它们分别解码就得到了如下数据:
1 | |
这下就明白了为什么JWT的J是JSON了吧
Header
在标准的JWT中,Header包括Token的类型和算法名称。
Token好理解,本文都是JWT,自然就是JWT
而算法则是决定服务器那端如何解码的,例如这里使用HS512,则意味着签名是HS512得到的。
Payload
标准JWT中,Payload包含声明(要求)。声明是关于实体(通常是用户)和其他数据的声明。声明有三种类型: registered, public 和 private1。
- Registered claims : 这里有一组预定义的声明,它们不是强制的,但是推荐。比如:iss (issuer), exp (expiration time), sub (subject), aud (audience)等。
- Public claims : 可以随意定义。
- Private claims : 用于在同意使用它们的各方之间共享信息,并且不是注册的或公开的声明。
标准文档比较难读懂,说白话,这里的Payload就是自定义信息,只不过携带一点标准信息罢了,比如上面这个
1 | |
| 字段 | 内容 | 用途 |
|---|---|---|
| iss | Issuer 签发人 | 可以用来存用户id |
| sub | Subject 主题 | 让服务器知道jwt用途 |
| aud | Audience 观众? | 文档没看懂 |
| nbf | Not Before 生效时间,unix秒级时间戳 | 早于nbf的时间不给过 |
| iat | Issued At 签发时间,unix秒级时间戳 | 让服务器知道这条jwt是正常的 |
| exp | Expiration Time 有效时间,unix秒级时间戳 | 告诉服务器这段jwt何时过期 |
| jti | JWT ID 字面意思 | 让服务器判断这是哪个jwt |
| 其它 | 用于存储其他自定义信息的字段 | 自定义的信息,用途无穷大 |
也就是说,jwt的这个部分可以是任意信息,剩余的那些只是约定俗成的而已,上面举例的那条也没有包含完整的字段。而用途也不是我列出来的这些,这里只是一个举例,不一定按照字段用途来进行使用。
Signature
这部分是服务器确定jwt没被篡改的关键,根据Header的算法字段,签名生成的方式如下
加密算法(base64(header).base64(payload), 秘钥)
秘钥可以是普通字符串,加解密使用对称加密;也可以是密钥对的私钥,加密时使用私钥,解密时使用公钥,加解密是非对称加密。
如果用户自行修改了Payload部分,服务器在使用前面的Header和Payload做一次签名的时候,发现新的签名和原始jwt签名不一样,则判定为假密钥
要注意,Payload和Header里面的一切数据都是明文,只不过使用了base64进行编码了,而base64不是加密的方式,任何人,任何计算机都可以轻松地还原base64字符串,所以请不要将敏感信息直接存储在jwt之中
所以jwt的数据结构就是这样的:base64(header).base64(payload).signature,使用.将三个部分连接起来就构成了jwt。
JWT使用
在这里,后端暂且使用nodejs来示范。
在nodejs中有一个库jsonwebtoken可以让你快速生成和验证jwt
在项目中安装该库 npm i jsonwebtoken
签发
JWT签发按照上文说的规范来进行,由base编码的Header,Payload与Signature签名算法用一个英文.符号拼接在一起得到。
在nodejs使用库来写是这样
1 | |
成功后输出jwt:eyJhbGciOiJIUzUxMiIsInR5cCI6IkpXVCJ9.eyJuYW1lIjoiRmlzY2hsIiwiaXNzIjoiQXItU3ItTmEiLCJpYXQiOjE3MTE4Nzg3NDcsImV4cCI6MTcxMTk2NTE0N30._EWieqB-bRrWCKJFEANiItzCQODoc2IucjLwnpPmrd63clABXQhgz8w3hF-xDAGruIyq_INILw90r8Y19mGBxA
不用过多解释了,很简单
使用方法是这样:
1 | |
而参数这里可以指定算法,有效期等,当然这部分仍然可以自定义,这里只展示最简单的方法,可以参照官方文档:https://www.npmjs.com/package/jsonwebtoken
验证
由于HMAC无法反向解密,所以只能靠再使用签发时的流程来验证
- 从传入的jwt中拿到Header,Payload
- 解码Header得到算法
- 使用Header中的算法,按照签发时的流程生成签名
- 与传入的jwt中的签名进行对比,如果完全一致则通过
1 | |
如果签名对得上,所有验证都通过之后输出Payload
如果jwt已经超过有效期,签名无效,格式不正确,都会抛出的错误,只需要进行try catch捕获,或者使用回调函数捕获即可。
应用-卡密和登录的实现
后端
我们依然以开头说的“卡密”为例子,讲一下这个jwt要怎么用,怎么签和怎么验。
比如我有一个服务器接口,只有当用户的卡密在有效期内,且用户是管理员,没有被封禁时才能正常调用。
分析一下需求:
- 卡密的有效期就是jwt的
exp字段 - 为了标识用户,用户需要一个UUID,这个放在
name字段 - 用户身份
id - 是否封禁
block
假设有这么两个用户:
1 | |
那么使用jsonwebtoken这个库签发的时候使用方法是这样
1 | |
这样就可以获得用户的jwt,剩下的就交给前端来处理了
在验证的时候,使用jwt.verify方法,验证基本信息(在有效期内,签名正确,格式正确)正确后进入自定义的认证,判断!block && id === 'normal',两者均通过之后,则正常返回数据,也可以从payload中获得name,再执行其他的操作,例如从数据库获取用户的余额等。
前端
jwt更多的是用在前端调用的,后端返回给前端后,需要一个地方来进行保存
而所谓的“登录态”“已激活”等状态,就是判断是否存储有相应的jwt
这里有几种方式,localStorage,cookie,sessionStorage,我比较推荐使用localStorage,虽然cookie更适合存储这些存在有效期的数据,但是jwt本身就有有效期的字段exp,只要每次请求先从前端判断exp是否有效,如果无效直接移除即可,而cookie的存储调用相对来说不是那么的方便,存储的大小也比localStorage小,还有保存上可能因为路径改变而丢失。
在请求的时候,例如使用fetch,可以在请求头header部分携带这个jwt,也可以在body,不过由于GET在服务器是没法获取body的,所以就放在了header。而header的规范一般是这样:Authorization: Bearer {jwt},至于怎么放,这个就得和后端协商协商了。
实际应用
在我们公司的AI站上,登录的流程就采用了JWT,不过涉及到隐私的问题,不能够跟你讲太多,在前端部分,跟上面说的是一样的,只不过header没有这么规范,当然,你也可以自己打开F12,登录后看看请求,拿自己的token使用公钥进行解析,这里推荐一个工具用来解析jwt:https://jwt.io,不过要注意,请不要泄露你的access_token,因为这条token是你用户的最高权力,一切后果自负。
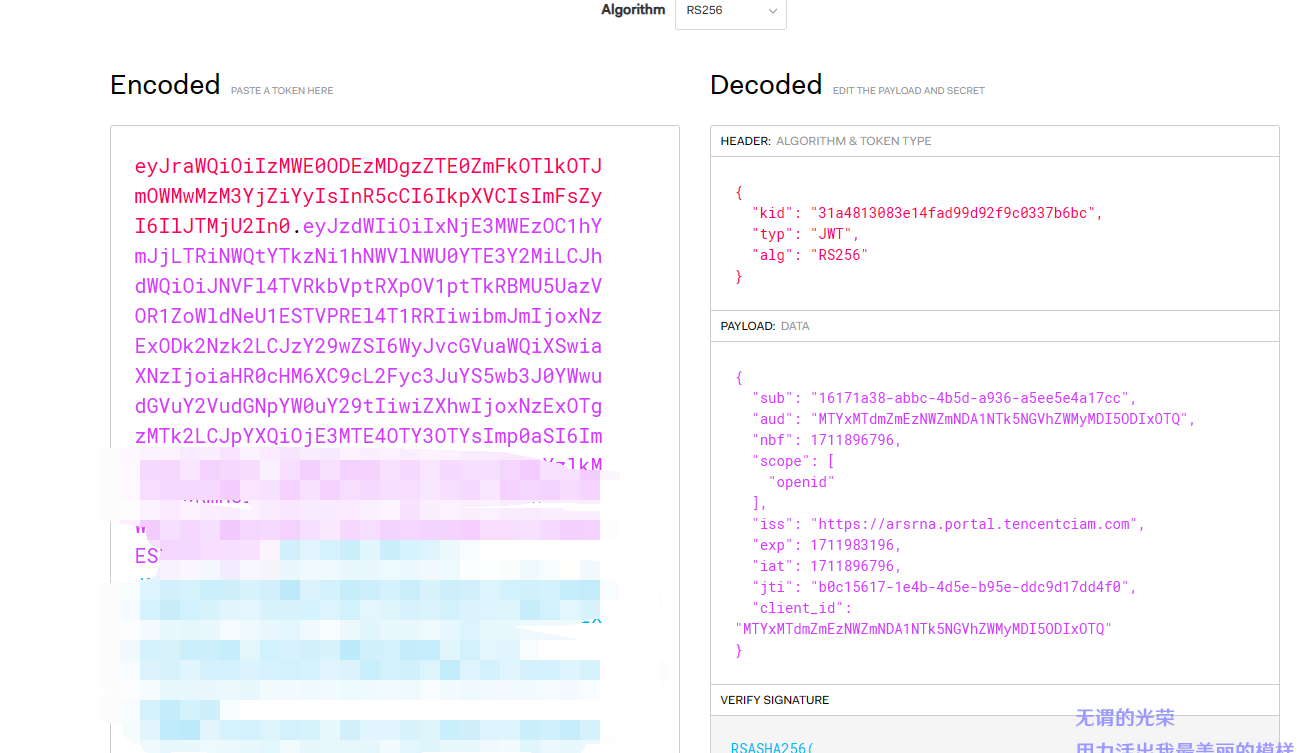
由于涉及到一些隐私上的算法,我没法告诉你公钥是什么,而且应用有多对公私钥,会随机地使用其中一对进行加解密,但是背后的核心jwt是永恒不变的。
当你请求登录的时候,经过一系列登录流程后就获得了你的access_token,id_token,它就是jwt,一个是专门用于给服务器请求的jwt,一个是个人基本信息展现在前端的jwt,我们的服务器会验证access_token上面的一切数据,确定用户是能够访问接口的,随后才会正式访问,与上一节的《【秒杀】前端网络-CORS》浏览器预检操作功能类似,都是检查用户是否有权访问服务器的前提条件。
总结
jwt就像你的个人档案,用人单位就是服务器,用人单位如何确定你档案里的信息是否有效,是否有篡改的可疑,就看封条是否被拆封。你的档案内容上面有姓名,身份证,国籍等等,这里就是jwt的Payload;而档案上面的档案号,就是Header,告诉阅档人员用什么样的方式去读取你的档案;封条则是JWT保护数据的核心,是否有篡改的嫌疑,就看封条是否完整,而jwt就是靠签名来判断是否篡改的。
虽然现实不太可能让你保管你的档案,不过我也找不到更合适的例子了。
Session就是让你的档案存在档案中心,你提供身份证号(Session Token),用人单位就从档案中心找你的档案,因为全国人的档案都在这里,找起来比较费时,而且这么多份存起来也麻烦。
jwt则是让档案保管在每个人手中,为了防止个人篡改,加入了签名,来验证档案的数据是否更改,这样用人单位从个人手中拿到档案的时候只需要检查封条完整就行了,大大减少了检索的压力,而且数据在用户手上,一切后果都是用户承担,也减轻了一部分的压力。
参考文献
[1] RFC 7519, JSON Web Token (JWT)
Powered by Ar-Sr-Na